|
Yongqiang Wang I am a staff research scientist at Google. At Google I've worked on Speech-to-text for Cloud, Universal Speech Model, and multimodal foundational models, for example AudioPaLM. Email / CV / Google Scholar / Github |

|
ResearchI'm interested in speech recognition and integrating speech understanding capabilities into multimodal foundational models. Some of the latest works are listed in the following. |
|
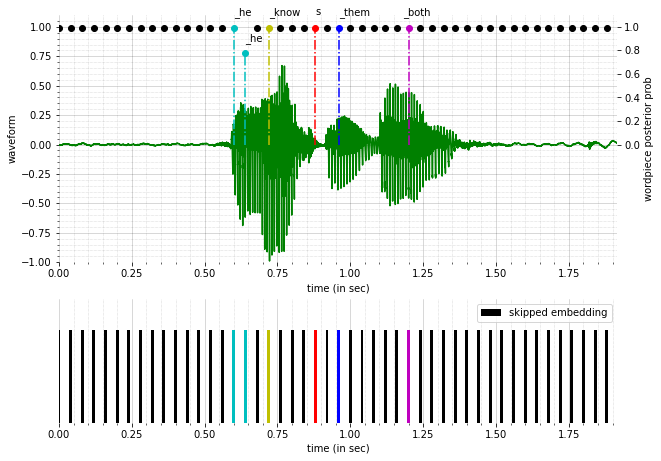
Accelerating RNN-T Training and Inference Using CTC guidance
Yongqiang Wang, Zhehuai Chen, Chengjian Zheng, Yu Zhang, Wei Han, Parisa Haghani ICASSP, 2023 We leverage the sparsity (both time and probability axes) of the CTC log posterior to accelerate the RNN-T training and inference. |
Miscellanea |
- Vision Language Model
- Sound Generation
- From VAE to diffusion models
|
Feel free to steal this website's source code. Do not scrape the HTML from this page itself, as it includes analytics tags that you do not want on your own website — use the github code instead. Also, consider using Leonid Keselman's Jekyll fork of this page. |